





Sound All Around: The Continuing Evolution of 3D Audio


Dolby’s Atmos system is one of many 3D audio delivery formats that are making sound more immersive in the 21st century.
Close your eyes and think about the last time you were at a gig. How did it sound? The band is rocking out on stage, your friends are talking in a group over to your left, a busboy says “excuse me” as he slides past your right shoulder, and the din of the crowd is all around. Sounds like a club, right?
The aim of 3D, or “spatial”, audio is to replicate these complete sonic environments—or to synthesize completely new ones.
With conventional stereo techniques, the sound stage is effectively limited to the space between the left and right speakers. But with the addition of more channels (and/or clever signal processing) 3D audio techniques aim to provide the perception of sound from any and all directions. With the rise of immersive entertainment and virtual reality, it is becoming an increasingly important area with many practical and creative applications.
The development of spatial sound began in the film industry in 1940 when Disney created the experimental 8-channel ”Fantasound” format for the groundbreaking Fantasia. To this day, the sector remains a key driver of spatial audio development, with formats like Dolby Atmos and Auro 3D pushing towards ever more immersive experiences to lure cinephiles out of their homes and into the theater.
But the move toward 3D audio is occurring in personal environments as well: In gaming, 3D audio is fast becoming just as crucial as 3D visuals for creating realistic environments for systems like the Oculus Rift and Playstation VR.
Augmented reality systems for motor vehicles are also beginning to use 3D sound techniques to provide distinguishable spatialized ”earcons” for drivers. And recently, Dolby announced it is adapting its Atmos system to provide 3D audio for nightclubs. This expandable multichannel format is already attracting major avant garde musicians, as well. At the AES 139th convention in October last year, Dolby and Kraftwerk demonstrated material from the forthcoming Kraftwerk 3D release for the Atmos system.
The increasing relevance of 3D audio has even been acknowledged by codec developers with the release of the MPEG-H standard, and as manufacturers, content creators, and consumers align themselves with the standard, we will likely see much more 3D content across a variety of platforms and formats.
How We Hear in Three Dimensions
To create believable and immersive 3D sound environments, we need to understand how our ears and brain “localize”—or perceive the directionality of—any given sound.
This is even more crucial for 3D than it is for stereo. In everyday life, we hear sounds coming from every direction. Somehow, our brain is able to process all this information, separate important elements from background noise, and determine where each element is coming from in three dimensional space.
Using sound cues, we can even quickly and unconsciously identify the size and type of space we are in. Are we in a field or front and center in a concert hall? Above a sound source or below it? In front of it or behind? How does the ear and brain determine all this?
The answers lie in the field of psychoacoustics, which has been an active research area for the last three quarters of a century. From this field of study, we have a broad—yet still incomplete—understanding of how our perceptions around sound localization are formed.
The main cues are “binaural” in nature, stemming from the physical separation between our two ears. When a sound source is off-center, there is a subtle time delay between the signal reaching the nearer ear and the further one. This “Interaural Time Difference” (or ITD) introduces a wavelength-dependent phase difference that the brain instantly interprets as a cue for direction. The further to the right a source is, the larger the delay between the sound reaching the right ear compared to the left. Phase differences become harder to detect at higher frequencies, so this cue is most effective below around 1-1.5 kHz.
But in addition to this simple time difference, the physical mass of your head absorbs sound energy as waves passes through from the ear nearest the source to the far ear. Conveniently, this shadowing effect—the “Interaural Level Difference” (ILD)—operates mainly for high frequencies, which are absorbed more than lower frequencies that tend to diffract.
The concept is easy to understand, and you exploit it whenever you use the basic two-dimensional pan pot on a conventional mixer. The more to the right a source is, the louder it will be in the right ear. A pan pot emulates this by increasing the level in the right channel compared to the left. For a phantom center image, both channels have the same level.
And what if a source is directly in front of the listener, but elevated slightly, or even above and behind the head? In such cases, there are no binaural differences to help us localize sounds. “Cones of confusion” describe the planes upon which binaural cues are ambiguous. Along such surfaces, the pinnae (the visible, outer part of our ears) help to localize sounds. Its complex folds give rise to multiple reflections that causes directionally-dependent filtering to occur before a sound enters the ear canal. These spectral cues are interpreted as direction.
All these binaural and spectral cues can be plotted and summarized with a measurement called the “Head Related Transfer Function” (HRTF), which describes the response of the two ears to sources at every point in space. Think of it as a bit like an impulse response for each ear from each and every direction. Since everyone’s head and ears differ in size and shape, our HRTFs are highly individual. Some general trends do exist however— for example, rear sources tend to have reduced high frequencies relative to frontal ones due to absorption by the rear of the pinnae.
The Significance of Space
Unless we are standing in an anechoic chamber, we also have to consider the effect of environmental reflections. These occur after the direct sound reaches our ears, and tend to come from all different directions. How do we determine which is the original source, and which is the reflected sound? These reflections form a crucial part of our spatial impressions.
The precedence effect helps us deal with these competing cues. When two identical sounds are played from different locations in rapid enough succession, they create a single perceived auditory event, rather than being localized separately. The exact effect depends on their relative time delay: Delays less than 1 ms between the first (leading) and the later (lagging) sound cause us to perceive a single fused auditory event, with the intensity and delay of the reflections influencing the perceived location.
For slightly longer delays, the two sounds remain perceptually fused, but are localized solely based on the position of the leading sound. If the delay is long enough, we will begin to perceive two separate sounds, and we hear the lag as a distinct echo with a location of its own.
This cue most likely evolved from the need for our ancestors to determine the direction of threats in reverberant environments such as caves, where they likely spent a good deal of time. (In fact, there’s evidence to suggest cave paintings were often made in some of the most reverberant regions of the caves in which they are found).
Playing with Nature
To create a realistic sonic environment, we want to emulate all these cues—binaural, spectral and environmental—as effectively as possible. The 3D audio techniques that allow us to do so range from virtual processing of stereo signals to the installation of elaborate multichannel systems. Each of these has their uses, advantages and disadvantages.
One of the oldest and most intuitive is Binaural Recording, which aims to directly capture the sound field as it would enter a person’s ears. In this format, a dummy head with microphones at the entrances of the ear canals is used to capture the sound field exactly as it would be heard by a person in the room. In a sense, it aims to capture sound sources with a physical, acoustic Head Related Transfer Function applied. When played back via headphones, the recorded HRTF cues are piped right into the listener’s ears. Check out the ‘virtual barbershop’ demo on YouTube for an example.
A recording can also be ‘binauralized’ by convolving it with the appropriate HRTF dataset. Free HRTF datasets are available online (such as IRCAM or MIT’s KEMAR) if you want to try it with your favorite convolution plugin.
The problem with binaural recording is that these HRTF cues breakdown when headphones are not used. With loudspeakers, the signal for the left ear (coming from the left speaker) also reaches the right ear, and vice versa. This “crosstalk” interferes with each ear’s specific localization cues. We are used to hearing stereo music in this way and it has been mixed with this limitation in mind, but for a true binaural effect it just doesn’t work. Crosstalk also explains why music over headphones can sound ‘internalized’ in our heads – it has been mixed in an environment with crosstalk, but we don’t get that full picture when each ear receives an isolated signal.
Up until recently, crosstalk cancellation methods used complex, recursive digital filtering to remove the crosstalk, but this usually left the resulting signal too colorized to be of any real use. Recently, more advanced techniques such as the one employed by the BACCH 3D SP processor created by Edgar Choueri and his team at Princeton University’s 3D Audio and Applied Acoustics Lab have overcome many of the existing problems with crosstalk cancellation. This new process also works with normal stereo material by allowing the localization cues captured by stereo mic techniques to come across fully.
3D Surround
When it comes to multichannel loudspeaker systems, a number of approaches are possible.
Some systems extend the concept of 5.1-surround sound by adding additional channels. In particular, height channels above or below the horizontal plane extend the sound field vertically.
Psychoacoustic research has shown that vertical reflections are crucial to our perception of an acoustic space, and that height channels can enhance the horizontal width of the images beyond the stereo basis. In addition to increasing the sense of spaciousness and envelopment, adding in these height layers can also help overcome some of the problems found in traditional surround sound, such as lateral panning instabilities.
The Auro-3D format adds a layer of height channels above the standard 5.1-surround layer, at a height of half the stereo basis (L-R distance). In the 9.1 configuration, four extra speakers are placed in this layer above front and surround speakers. Extending this even further with a ‘Voice of God’ channel directly above the sweet spot leads to a 10.1 designation. Additional channels (up to 13.1) can be added for large-scale cinema installations. The Auro-3D system also contains processing hardware that can upmix from conventional 5.1 or 7.1 and simulate the extra height information.
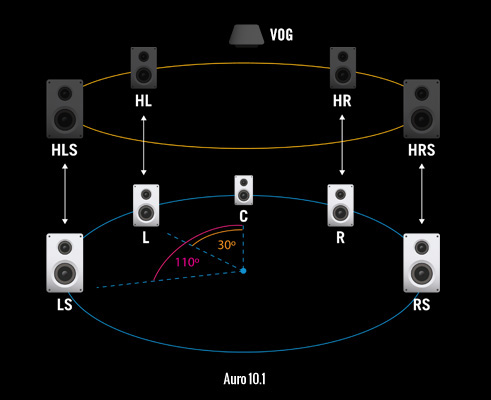
The Auro10.1 Format
The NHK 22.2 system, developed in conjunction with the Super Hi-Vision 8K UHD television standard, uses twenty-two full range channels arranged in three layers vertical and two subwoofers. The idea is that employing twenty-two distinct channels of audio provides adequate three-dimensional spatial impression and listener envelopment when used in conjunction with a screen.
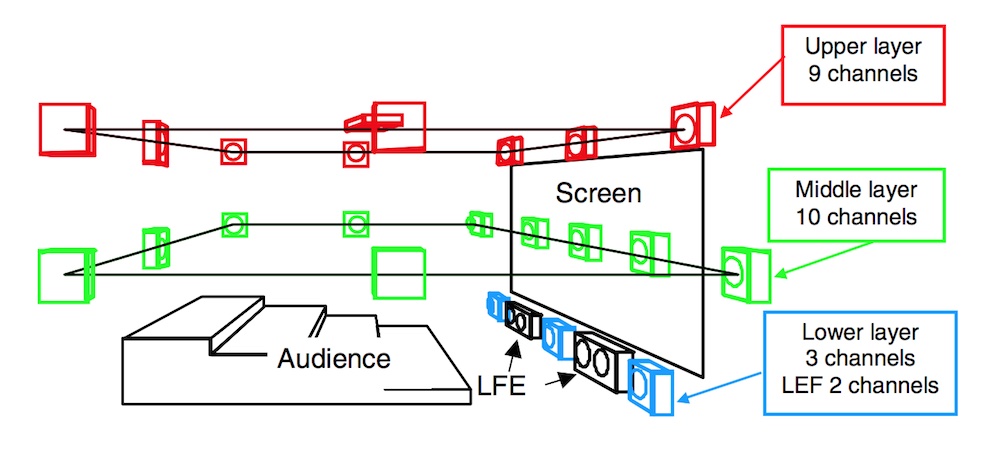
NHK 22.2 system, image from Hamasaki et al; AES Convention Paper 6226, 2004.
All these techniques can effectively add vertical information and increase realism. However they are still rooted in the channel-based concepts of stereo and surround, that is, the correct number of speakers placed at the correct locations in a room. Engineers must mix to the specific speaker configuration with conventional panning techniques and so on.
Objective Audio
A more novel concept in multichannel audio is that of object-based audio. Rather than the transmission channels containing signals for each individual speaker, the sound field is described in terms of sound objects—individual sources or groups of sources that behave together.
In this paradigm, the signal contains metadata that describes where in space each of these objects is located. In the playback system, a renderer takes into account the room’s specific speaker configuration and derives the speaker signals that correspond to that positioning as closely as possible. The strength of this concept is adaptability and scalability. Sound designers and mix engineers no longer need to worry about the speaker configuration in playback environments – instead they can focus on crafting the aesthetics of a mix.
The concept of rendering environment-specific speaker signals is not necessarily new—the “Ambisonics” system from the 1970s was based on this idea—but advances in computer power and digital signal processing techniques have made the idea much more effective today than when the concept was first introduced.
Dolby Atmos is perhaps the most widely known example of an object-based system. With up to 128 audio tracks, mixing engineers can use a Pro Tools plugin or an Atmos console (the AMS Neve DFC or Harrison MPC5) to spatialize sound. The renderer then decodes the object position metadata into feeds for each speaker.
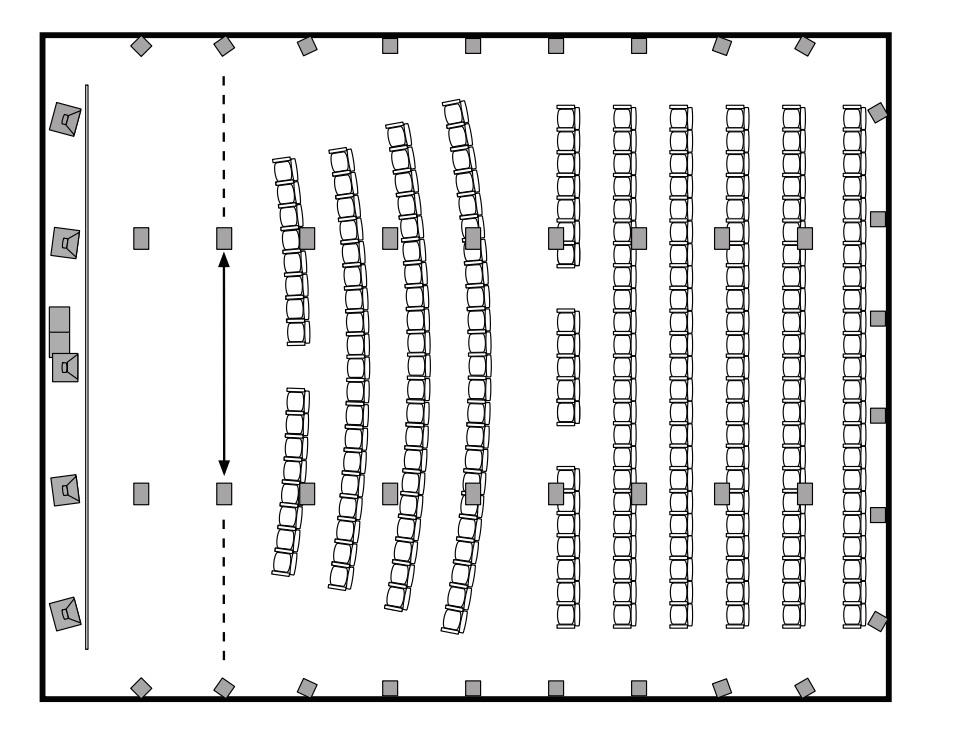
Overhead view of an Atmos system.
In the cinema space, Atmos and Auro-3D are currently competing for market share. Both formats have seen some major studio releases, but Dolby probably has the upper hand, due to its pre-existing position in the cinema market.
Making Waves
Finally, Wave Field Synthesis (WFS) takes a completely different approach to creating a three-dimensional sound field. Unlike other systems, it aims to recreate an image that does not change or depend on the listener’s position.
It is based on the Huygens-Fresnel principle, which states that any point on a wavefront can be thought of as a new source of spherical waves, and that the wavefront at any later time can be thought of as the superposition of all these spherical waves as they propagate through time and space. Using a dense array of loudspeakers, these spherical components can be actuated to create the soundfield of virtual sources positioned somewhere behind the loudspeaker array.
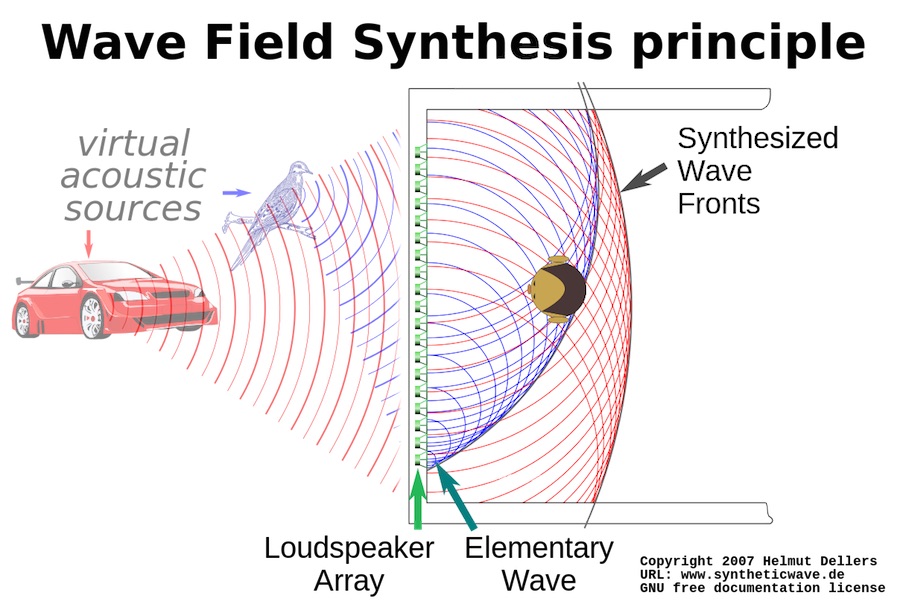
Visualization of the Wave Field Synthesis principle.
Because it does not aim to recreate the sound field only at the listening position (sweet spot), but rather throughout an entire environment, our perceptions don’t change as we move. The most obvious tradeoff is that it requires a lot of speakers and signal processing to calculate the reproduce the required density of point sources. Room reflections also have to be carefully controlled due to the delicate nature of the generated sound field.
There are plenty of other techniques that draw on similar concepts. For example, virtual 3D systems use HRTF filtering to create ‘virtual height channel’ signals played through conventional surround speakers. Dolby Pro Logic IIz uses upwards-pointing speakers attached to the surround layer speakers to create ceiling reflections.
The ultimate aim of 3D audio is to provide the additional information that our ears need to perceive sound coming from all directions. While there is a lot of science informing the technological side, the artistic possibilities are only just beginning to be explored.
To actually create content for these systems requires not only a whole new set of tools, but a whole new set of approaches. In the next article, we’ll discuss how to actually generate material for these systems—either with native recording or upmixing techniques.
bradfordswanson
February 4, 2016 at 6:11 pm (9 years ago)Great article. Thank you!
Theron Kaye
February 12, 2016 at 3:08 pm (9 years ago)That example is amazing.