





Why (Almost) Everything You Thought You Knew About Bit Depth Is Probably Wrong

A lot of competent audio engineers working in the field today have some real misconceptions and gaps in their knowledge around digital audio.
Not a month goes by that I don’t encounter an otherwise capable music professional who makes simple errors about all sorts of basic digital audio principles – The very kinds of fundamental concepts that today’s 22 year-olds couldn’t graduate college without understanding.
There are a few good reasons for this, and two big ones come to mind immediately:
The first is that you don’t really need to know a lot about science in order to make great-sounding records. It just doesn’t hurt. A lot of people have made good careers in audio by focusing on the aesthetic and interpersonal aspects of studio work, which are arguably the most important.
(Similarly, a race car driver doesn’t need to know everything about how his engine works. But it can help.)
The second is that digital audio is a complex and relatively new field – its roots lie in a theorem set to paper by Harry Nyquist 1928 and further developed by Claude Shannon in 1946 – and quite honestly, we’re still figuring out how to explain it to people properly.
In fact, I wouldn’t be surprised if a greater number of people had a decent understanding of Einstein’s theories of relativity, originally published in 1905 and 1916! You’d at least expect to encounter those in a high school science class.
If your education was anything like mine, you’ve probably taken college level courses, seminars, or done some comparable reading in which well-meaning professors or authors tried to describe digital audio with all manner of stair-step diagrams and jagged-looking line drawings.
It’s only recently that we’ve come to discover that such methods have led to almost as much confusion as understanding. In some respects, they are just plain wrong.
What You Probably Misunderstand About Bit Depth
I’ve tried to help correct some commonly mistaken notions about ultra-high sampling rates, decibels and loudness, the real fidelity of historical formats, and the sound quality of today’s compressed media files.
Meanwhile, Monty Montgomery of xiph.org does an even better job than I ever could of explaining how there are no stair-steps in digital audio, and why “inferior sound quality” is not actually among the problems facing the music industry today.
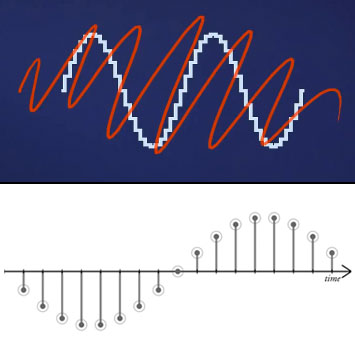
A bad way, and a better way to visualize digital audio. Images courtesy Monty Montgomery’s Digital Show and Tell video. (Xiph.org)
After these, some of the most common misconceptions I encounter center around “bit depth.”
Chances are that if you’re reading SonicScoop, you understand that the bit depth of an audio file is what determines its “dynamic range” – the distance between the quietest sound and the loudest sound we can reproduce.
But things start to go a little haywire when people start thinking about bit depth in terms of the “resolution” of an audio file. In the context of digital audio, that word is technically correct. It’s only what people think the word “resolution” means that’s the problem. For the purpose of talking about audio casually among peers, we might be even better off abandoning it completely.
When people imagine the “resolution” of an audio file, they tend to immediately think of the “resolution” of their computer screen. Turn down the resolution of your screen, and the image gets fuzzier. Things get blockier, hazier, and they start to lose their clarity and detail pretty quickly.
Perfect analogy, right? Well, unfortunately, it’s almost exactly wrong.
All other things being equal, when your turn down the bit depth of a file, all you’ll get is an increasing amount of low-level noise, kind of like tape hiss. (Except that with any reasonable digital audio file, that virtual “tape hiss” will be far lower than it ever was on tape.)
That’s it. The whole enchilada. Keep everything else the same but turn down the bit depth? You’ll get a slightly higher noise floor. Nothing more. And, in all but extreme cases, that noise floor is still going to be – objectively speaking – “better” than analog.
On Bits, Bytes and Gameboys
This sounds counter-intuitive to some people. A common question at this point is: “But what about all that terrible low-resolution 8-bit sound on video games back in the day? That sounded like a lot more than just tape hiss.”
That’s a fair question to ask. Just like with troubleshooting a signal path, the key to untangling the answer is to isolate our variables.
Do you know what else was going on with 8-bit audio back in the day? Here’s a partial list: Lack of dither, aliasing, ultra-low sampling rates, harmonic distortion from poor analog circuits, low-quality dither, low-quality DA converters and filters, early digital synthesis, poor quality computer speakers… We could go on like this. I’ll spare you.
Nostalgia, being one of humanity’s most easily renewable resources, has made it so that plenty of folks around my age even remember some of these old formats fondly. Today there are electronic musicians who make whole remix albums with Nintendos and Gameboys, which offer only 4 bits of audio as well as a myriad of other, far more significant issues.
(If you like weird music and haven’t checked out 8-Bit Operators’ The Music of Kraftwerk, you owe it to yourself. They’ve also made tributes to Devo and The Beatles.)
But despite all that comes to mind when we think of the term “8 Bits,” the reality is that if you took all of today’s advances in digital technology and simply turned down the bit depth to 8, all you’d get is a waaaaaaay better version of tape cassette.
There’d be no frequency problems, no extra distortion, none of the “wow” and “flutter” of tape, nor the aliasing and other weird artifacts of early digital. You’d just have a higher-than-ideal noise floor. But with at least 48 dB of dynamic range, even the noise floor of modern 8-bit audio would still be better than cassette. (And early 78 RPM records, too.)
Don’t take my word for it. Try it yourself! Many young engineers discover this by accident when they first play around with bit-crushers as a creative tool, hoping to emulate old video game-style effects. They’ll often become confused and even disappointed to find that simply lowering the bit count doesn’t accomplish 1/50th of what they were hoping for. It takes a lot more than a tiny touch of low-level white noise to get a “bad” sounding signal.
The Noise Floor, and How It Effects Dynamic Range
This is where the idea of “dynamic range” kicks in.
In years past, any sound quieter than a certain threshold would disappear below the relatively high noise floor of tape or vinyl.
Today, the same is true of digital, except that the noise floor is far lower than ever before. It’s so low, in fact, that even at 16 bits, human beings just can’t hear it.
An 8-bit audio file gives us a theoretical noise floor 48dB below the loudest signal it can reproduce. But in practice, dithering the audio can give us much more dynamic range than that. 16-bit audio, which is found on CDs, provides a theoretical dynamic range of 96dB. But in practice it too can be even better.
Let’s compare that to analog audio:
Early 78 RPM records offered us about 30-40 dB of dynamic range, for an effective bit depth of about 5 -6 bits. This is still pretty useable, and it didn’t stop people from buying 78s back in the day. It can even be charming. It’s just nowhere near ideal.
Cassette tapes started at around 6 bits worth of “resolution”, with their 40 dB of dynamic range. Many (if not most) mass-produced cassettes were this lousy. Yet still, plenty of people bought them.
If you were really careful, and you made your tapes yourself on nice stock and in small batches, you could maybe get as much as 70dB of dynamic range. This is about equivalent to what you might expect out of decent vinyl.
Yes, it’s true, it’s true. Our beloved vinyl, with its average dynamic range of around 60-70dB, essentially offers about 11 bits worth of “resolution.” On a good day.
Professional-grade magnetic tape was the king of them all. When the first tape players arrived in the U.S. after being captured in Nazi Germany at the end of World War II, jaws dropped in the American music community. Where was the noise? (And you could actually edit and maybe even overdub? Wow.)
By the end of the tape era, you could get anywhere from 60dB all the way up to 110dB of dynamic range out of a high-quality reel – provided you were willing to push your tape to about 3% distortion. Those were the tradeoffs. (And even today, some people still like the sound of that distortion in the right context. I know I do.)
Digital can give us even more signal-to-noise and dynamic range, but at a certain point, it’s our analog circuits that just can’t keep up. In theory, 16-bit digital gives us 96 dB of dynamic range. But in practice, the dynamic range of a 16-bit audio file can reach well over 100 dB – Even as high as 120 dB or more.
This is more than enough range to differentiate between a fly on the wall halfway across your home and a jackhammer right in front of your face. It is a higher “resolution” than any other consumer format that came before it, ever. And, unless human physiology changes over some stretch of evolution, it will be enough “resolution” for any media playback, forever.
Audio capture and processing however, are a different story. Both require more bits for ideal performance. But there’s a limit as to how many bits we need. At a certain point, enough is enough. Luckily, we’ve already reached that point. And we’ve been there for some time. All we need to do now is realize it.
Why More Bits?
Here’s one good reason to switch to 24 bits for recording: You can be lazy about setting levels.
24 bits gives us a noise floor that’s at least 144 dB below our peak signal. This is more than the difference between leaves rustling in the distance and a jet airplane taking off from inside your home.
This is helpful for tracking purposes, because you have all that extra room to screw up or get sloppy about your gain staging. But for audio playback? Even super-high-end audiophile playback? It’s completely unnecessary.
Compare 24-bit’s 144 dB of dynamic range to the average dynamic range of commercially available music:
Even very dynamic popular music rarely exceeds 4 bits (24dB) or so worth of dynamic range once it’s mixed and mastered. (And these days, the averages are probably even lower than that, much to the chagrin of some and the joy of others.) Even wildly dynamic classical music rarely gets much over 60 dB of dynamic range.
But it doesn’t stop there: 24-bit consumer playback is such overkill, that if you were able to set your speakers or headphones loud enough so that you could hear the quietest sound possible above the noise floor of the room you were in (let’s say, 30db-50dB) then the 144 dB peak above that level would be enough to send you into a coma, perhaps even killing you instantly.
The fact is, that when listening to recorded music at anything near reasonable levels, no one is able to differentiate 16-bit from 24-bit. It just doesn’t happen. Our ears, brains and bodies just can’t process the difference. To just barely hear the noise floor of dithered 16 bit audio in the real world, you’d have to find a near-silent passage of audio and jack your playback level up so high that if you actually played any music, you’d shear through speakers and shatter ear drums.
(If you did that same test in an anechoic chamber, you might be able to get away with near-immediate hearing loss instead. Hooray anechoic chambers.)
But for some tasks, even 24-bits isn’t enough. If you’re talking about audio processing, you might go higher still.
32 Bits and Beyond
Almost all native DAWs use what’s called “32-bit Floating Point” for audio processing. Some of them might even use 64 bits in certain places. But this has absolutely no effect on either the raw sound “quality” of the audio, or the dynamic range that you’re able to play back in the end.
What these super-high bit depths do, is allow for additional processing without the risk of clipping plugins and busses, and without adding super-low levels of noise that no one will ever hear. This extra wiggle room lets you do insane amounts of processing and some truly ridiculous things with your levels and gain-staging without really thinking twice about it. (If that happens to be your kind of thing.)
To get the benefit of 32-bit processing, you don’t need to do anything. Chances are that your DAW already does it, and that almost all of your plugins do too. (The same goes for “oversampling,” a similar technique in which an insanely high sample rate is used at the processing stage).
Some DAWs also allow the option of creating 32-bit float audio files. Once again, these give your files no added sound quality or dynamic range. All this does is take your 24-bit audio and rewrite it in a 32-bit language.
In theory, the benefit is that plugins and other processors don’t have to convert your audio back and forth between 24-bit and 32-bit, thereby eliminating any extremely low-level noise from extra dither or quantization errors that no one will ever hear.
To date, it’s not clear whether using 32-bit float audio files are of any real practical benefit when it comes to noise or processing power. The big tradeoff is that they do make all of your projects at least 50% larger. But if you have the space and bandwidth to spare, it probably can’t hurt things any.
Even if there were a slight noise advantage at the microscopic level, it would likely be smaller than the noise contribution of even one piece of super-quiet analog gear.
Still, if you have the disk space and do truly crazy amounts of processing, why not go for it? Maybe you can do some tests of your own. On the other hand, if you mix on an analog desk you stand to gain no advantage from these types of files. Not even a theoretical one.
A Word On 48-bit
Years ago, Pro Tools, probably the most popular professional-level DAW in America, used a format called “48-Bit Fixed Point” for its TDM line.
Like 32-bit floating, this was a processing format, and it had pretty much nothing to do with audio capture, playback, or effective dynamic range.
The big difference was in how it handled digital “overs”, or clipping. 32-bit float is a little bit more forgiving when it comes to internal clipping and level-setting. The tradeoff is that it has a potentially higher, and less predictable noise floor.
The noise floor of 48-bit fixed processing was likely to be even lower and more consistent than 32-bit float, but the price was that you’d have to be slightly more rigorous about setting your levels in order to avoid internal clipping of plugins and busses.
In the end, the differences between the two noise floors is basically inaudible to human beings at all practical levels, so for simplicity’s sake, 32-bit float won the day.
Although the differences are negligible, arguing about which one was better took up countless hours for audio forum nerds who probably could have made better use of that time making records or talking to girls.
All Signal, No Noise
To give a proper explanation of the mechanics of just how the relationship between bit depth and noise floor works (and why the term “resolution” is both technically correct and so endlessly misleading for so many people) would be beyond the scope of this article. It requires equations, charts, and quite possibly, more intelligence than I can muster.
The short explanation is that when we sample a continuous real-world waveform with a non-infinite number of digital bits, we have to fudge that waveform slightly in one direction or another to have it land at the nearest possible bit-value. This waveform shifting is called a “quantization error,” and it happens every time we capture a signal. It may sound counter-intuitive, but this doesn’t actually distort the waveform. The difference is merely rendered as noise.
From there, we can “dither” the noise, reshaping it in a way that is even less noticeable. That gives us even more dynamic range. At 16 bits and above, this practically unnecessary. The noise floor is so low that you’d have to go far out of your way to try and hear it. Still, it’s wise to dither when working at 16 bits, just to be safe. There are no real major tradeoffs, and only a potential benefit to be had. And so, applying dither to a commercial 16-bit release remains the accepted wisdom.
Now You Know
If you’re anything like me, you didn’t know all of this stuff, even well into your professional career in audio. And that’s okay.
This is a relatively new and somewhat complex field, and there are a lot of people who can profit on misinforming you about basic digital audio concepts.
What I can tell you is that the 22-year olds coming out of my college courses in audio do know this stuff. And if you don’t, you’re at a disadvantage. So spread the word.
Thankfully, lifelong learning is half the point of getting involved in a field as stimulating, competitive and ever-evolving as audio or music.
Keep on keeping up, and just as importantly, keep on making great records on whatever tools work for you – Science be damned.
me
August 29, 2013 at 12:50 pm (11 years ago)Sooo wrong, don’t even know where to begin… I will just unsub, total waste of time…
Russ Hughes
August 29, 2013 at 11:03 pm (11 years ago)I’d begin with learning how to spell the word ‘so’
Matt S
August 30, 2013 at 6:30 am (11 years ago)Begin with the first incorrect statement in the article. It shouldn’t be hard, unless “don’t know where to begin” is code for “don’t have data to back up my position.”
Adam
September 2, 2013 at 9:44 pm (11 years ago)I’ll bite. The “potential” benefit of always dithering when reducing bit depth (not “bit rate”), while sometimes subjective, is objectively very real. This is for two simple reasons:
Firstly, the issue is not one of just noise but of retaining and resolving meaningful signal within the noise.
And secondly, because the effect of NOT dithering (truncation distortion) is cumulative with every single stage of processing, gain changing, etc., and the level of this distortion is greater than that of the (random) dither noise.
– full-time mastering engineer.
Bobby
September 11, 2013 at 12:25 pm (11 years ago)Ok so you found 2 discrepancies that needed clearing up. I guess you did know where to begin. Are there other things that are wrong? Or is the article in fact full of good info with 2 inaccuracies about dithering?
– part-time mastering engineer
mojobone
September 30, 2013 at 12:40 pm (11 years ago)Yes, there is another statement I find questionable: some people apparently can distinguish between 16-bit and 24-bit audio files, under certain circumstances; those circumstances usually involve a carefully-controlled listening environment and highly trained ears, but it’s not at all subjective, certainly enough people claim to have proven it in double-blind testing.
The
fact is, that when listening to recorded music at anything near
reasonable levels, no one is able to differentiate 16-bit from 24-bit.
It just doesn’t happen. Our ears, brains and bodies just can’t process
the difference. To just barely hear the noise floor of dithered 16 bit
audio in the real world, you’d have to find a near-silent passage of
audio and jack your playback level up so high that if you actually
played any music, you’d shear through speakers and shatter ear drums. –
See more at:
https://www.sonicscoop.com/2013/08/29/why-almost-everything-you-thought-you-knew-about-bit-depth-is-probably-wrong/#sthash.L4DpDQIv.dpuf
The
fact is, that when listening to recorded music at anything near
reasonable levels, no one is able to differentiate 16-bit from 24-bit.
It just doesn’t happen. Our ears, brains and bodies just can’t process
the difference. To just barely hear the noise floor of dithered 16 bit
audio in the real world, you’d have to find a near-silent passage of
audio and jack your playback level up so high that if you actually
played any music, you’d shear through speakers and shatter ear drums. –
See more at:
https://www.sonicscoop.com/2013/08/29/why-almost-everything-you-thought-you-knew-about-bit-depth-is-probably-wrong/#sthash.L4DpDQIv.dpuf
The
fact is, that when listening to recorded music at anything near
reasonable levels, no one is able to differentiate 16-bit from 24-bit.
It just doesn’t happen. Our ears, brains and bodies just can’t process
the difference. To just barely hear the noise floor of dithered 16 bit
audio in the real world, you’d have to find a near-silent passage of
audio and jack your playback level up so high that if you actually
played any music, you’d shear through speakers and shatter ear drums. –
See more at:
https://www.sonicscoop.com/2013/08/29/why-almost-everything-you-thought-you-knew-about-bit-depth-is-probably-wrong/#sthash.L4DpDQIv.dpuf“
Ricardus
September 30, 2013 at 1:15 pm (11 years ago)Every double blind test I’ve seen shows close to a 50% hit rate. Might as well be guessing. No one can hear the difference.
mojobone
October 2, 2013 at 9:52 am (11 years ago)I’m not talking about the sort of low-level noise that while measurable, is not perceptible by humans; I’m talking about an accumulation of errors not always represented in even 16-bit, 44.1kHz audio. I agree with the author regarding stair-stepping, zipper noise, quantization errors, etc; taken individually, (and given there’s a pretty good error-correction scheme built into the format) none of these should be hearable, let alone objectionable, but in the aggregate, they can sometimes be perceived by some persons under some circumstances. Those persons usually being mastering engineers in mastering rooms; no anechoic chamber required.
Theoretically, given proper gain-staging and level management, there should be no audible difference between music captured at 16 and 24 bits and the same sample rate, but in the real world, as soon as you start reducing dynamic range, you begin to lose detail, which is only a problem if you like to hear details in your audio.The AD converter used probably has more to do with this than the format.
With the loudness wars declared over, (levels compensation algorithms have supposedly made hyper-compressing pointless) the only remaining justification for reducing dynamic range are artistic license and the idea that the work will likely be downsampled and degraded later through lossy forms of data compression.
Richard Nash
September 1, 2013 at 1:15 pm (11 years ago)what’s wrong, in your opinion?
Chuck Zwicky
August 29, 2013 at 1:03 pm (11 years ago)Thank you for the excellent article. I am glad to see that people are becoming more aware of how digital audio technology actually works and especially glad to see age old knee-jerk responses falling off into the noise floor. It might be interesting to your readers to learn that the most state of the art converters available cannot resolve more that 18 bits of data, A/D or D/A, despite what some manufacturers claim. It is impossible to build an audio circuit with a dynamic range of greater than 129dB without taking extreme measures and resorting to some pretty unconventional practices (often involving liquid nitrogen) as Scotty from Star Trek says “You cannot break the laws of Physics” . I still get projects to mix that are recorded at 16/44.1 and they sound every bit as good as every other format once I’m done. As I often say “If bit depth / sample rate is a problem getting in the way of making a great sounding record, you’ve got other problems”.
Ethan Winer
August 29, 2013 at 1:13 pm (11 years ago)Excellent article Justin. I’m always amused at people who throw stones yelling “You’re wrong” without ever explaining what’s wrong or, better, what’s right. And kudos for linking to Monty’s excellent video. If everyone would just take the time to watch that and *understand* what it’s explaining, there would be a lot less misunderstanding in audio forums!
Jamey Staub
August 29, 2013 at 4:31 pm (11 years ago)Justin, great article. You have answered questions that I have pondered. I agree with Chuck’s pun that 44.1/16 can sound every “bit” as good as other formats. Thanks for the knowledge.
S. Vaughan Merrick
August 29, 2013 at 4:32 pm (11 years ago)Great article Justin! I might add that 32 bit floating point files are 24 bit files with an 8 bit exponent file which only describes volume data within the DAW. It is not another 8 bits of dynamic resolution to the audio file from the fixed point conversion at the A-D stage. Files that are recorded with 24 bit converters become 32 bit floating point files while they are loaded into a DAW. Whether or not that data is then saved to disk is up to the user’s discretion (generally speaking this is a superfluous step). 32 bit floating point processing means that the 24 bit file created at the fixed point conversion will not suffer from word length truncation that is possible with fixed bit processing.
TrustMeI'mAScientist
August 31, 2013 at 2:20 pm (11 years ago)Thanks for the kind words Vaughan!
True story. I tried to explain that to the best of my ability in the second-to-last section of the article, but you’ve done it perhaps better than I!
Cheers,
Justin
codehead
August 14, 2017 at 6:22 pm (7 years ago)Good comment, so hate to be picky with details, but 32-bit floats actually encode 25 bits of precision along with the 8-bit exponent. (It does this by keeping the mantissa “normalized”, at 1.xxxxxx raised to the exponent, and omitting the leading “1”. Specifically, the mantissa uses 23 bits, a sign bit, and the implied bit, for 25-bits.)
Mark Waldrep
August 31, 2013 at 4:32 pm (11 years ago)As someone who teaches this stuff at the university level AND produces recordings in high-definition (96kHz/24-bits), there are recordings that benefit from 24-bits and higher than 44.1 sample rates. But Justin is right that most commercial pop/rock records don’t get even close to eclipsing the specs of Compact Discs. I post everyday at realHD-Audio (dot) com about this stuff and have a different perspective. There’s even some free HD-Audio downloads at the site that demonstrate the advantages of HD specifications all the way through the production process.
Think larger than the existing, limited record business and you might engage with truly better sound. It’s more than just specifications but we have the ability to record and deliver at 96 kHz/24-bits…so why not? The new NIN recording is available as a heavily mastered CD or as an audiophile version for those that want less “punch” in their music. It can go all the way to acquiring tracks that aren’t mastered at all…this coming from a guy that spent 13 years mastering projects for Bad Company, The Allman Brothers and lots of others.
There’s lots of commercially available recordings that have better than CD dynamic levels…I know my 100 albums do!
Dreadrik
October 1, 2013 at 12:51 am (11 years ago)But there are no double blind tests in the world that agrees with you. No humans have super-human hearing. Increasing the sample rate to 96kHz can actually be worse than using 44.1kHz, since you need to have proper equipment to handle the ultra sonic frequencies (that no human will ever hear), just so that they don’t introduce actual audible distortion.
This is a disadvantage to just distributing audio with lower resolution while at the same just wasting bandwidth. See this article, that has sound examples: http://xiph.org/~xiphmont/demo/neil-young.html
seewhyaudio .
February 12, 2014 at 8:27 am (11 years ago)As usual this opinion is stated as fact when it is very much still open to discussion. For one thing, double-blind tests ‘prove’ nothing more than a subject’s inability to distinguish between two sets of data within the confines of a test scenario. They do NOT prove that Hi-Res is inferior or superior. I always fail them, in their context.
But I also really love Hi-Res music, because I enjoy it more. Repeatedly. So, which data is now the proof? The ‘test’ that proves nothing or the ‘opinion’ that is repeated through experience and personal enjoyment? The answer of course is: neither.
In real life, the effects of the difference between 44.1/16 and 96/24 or above are nebulous and almost impossible to nail down. They are easier to feel.
The reference to ‘no human having super-human hearing’ is also guilty of being nowhere near the whole truth.
The ability to hear is an incredibly complex mixture of frequencies, amplitude, positional timing, context, sequencing and any combination of the above.
Moreover any one person CAN have better hearing than any other person for one of so many reasons that it’s not logical to even respond to your argument in that context. A piano tuner will have ridiculously keen sense of frequency, a percussionist might have a better sense of timing, a PIANIST might have both.
YOU the ‘subject’ of the ‘double-blind’ test might have neither, so whyon earth given all the above, would you even refer to them? They prove nothing.
And finally, I have yet to be shown an example of when going to 96/24 makes things ‘worse’. I’m still waiting and willing to be proven wrong but it ain’t happened yet.
Dreadrik
February 12, 2014 at 8:56 am (11 years ago)Well, double blind tests are the only tests that removes the subjective component of the sound, the “feeling” you get when you KNOW you are listening to HD audio. You should not underestimate the power of that feeling, but it’s really your mind playing a trick on you. If it makes you feel better, then go for it.
As for examples of 96/24 making sound worse, there is a perfect example complete with sound files for you to try out in the link I posted above.
seewhyaudio .
February 12, 2014 at 12:46 pm (11 years ago)Dreadrik? if you could explain how these tests remove the ‘subjective’ component I’d be most grateful. I think you’ll have trouble with that one.
Besides, that’s not my point.
I maintain that the absence of a positive ID between any two formats (in such a test) is a null result. It is not proof of no difference.
Surely the only kind of test with any purpose in this scenario would be one that the subject isn’t even aware was taking place? Or even what its purpose was? One that could be evaluated outside the realms of testing itself? That’s pretty hard to arrange but in other scenarios we shall simply call it ‘real life’.
And let me re-phrase the objection about 96/24 files being ‘worse’ than 44/16.
I’m perfectly aware of HF IM distortion.
The HF intermodulation samples that Monty at xiph.org kindly provides are perfectly good tools to show such effects can and do exist in virtually all digital systems (as they do on mine) but hells bells if I had a Hi-Res recording that displayed THAT much HF energy in the upper reaches above 20K, I’d expect nothing less than a bit of distortion. A tiny tiny bit, mind.
But honestly, when would you ever see a true audio recording of actually music that had anywhere near that kind of energy above 24k?
You don’t need to answer that. There are no such ‘true’ recordings.
So, it’s misleading to suggest that it’s a drawback of Hi-Res systems designed for replaying music and it’s misleading to state that there will be audible distortion in a real world application.
I reiterate, I have yet to experience such an effect and to the contrary, experience the opposite fairly often. Subjectively of course.
My problem is the opposite of yours, I can’t quantify it all. My yardstick is too subjective. Look, I’m quite happy to let my mind play tricks on me, even IF that is the only thing that’s happening (and I don’t believe it is), so long as it results in more enjoyment of what I’m listening to. I think it would be pretty hard to enjoy HR if I really thought it was pointless…
The thing is I don’t have an axe to grind against 44/16, I would love it if it were enough for me, the savings in disk-space, upload times, storage methods and replay opportunities would be very welcome indeed.
Sorry to say, my ears remain more satisfied by higher resolutions and beyond listener bias I have yet to understand how this could possibly be, other than the more prosaically obvious deduction that it actually sounds better somehow. How? I don’t really know and I’m not here to prove it.
To paraphrase Donald Rumsfeld, we have the known knowns and we have the known unknowns.
I wish Hi-Res critics would just open their minds a little to the very real possibility that they might be missing something precisely because they are looking so hard to disprove it’s a possibility.
Others have gone on record as to say that we still have very valid arguments that remain unsolved about our human hearing abilities. I would like to state for the record I am one of those people.
I put it to you that the very existence of these arguments is proof enough that we haven’t solved everything yet. I’m keeping an open mind.
Dreadrik
February 13, 2014 at 11:35 am (11 years ago)I find your assumption of how much HF energy there should be above 24kHz in a recording very interesting. How much noise is there between 22 and 48kHz in for example a recording studio? Or in your own house? One would have to have the equipment to measure it and display it visually for one to actually know.
No instruments are designed to be heard at frequencies above human hearing thresholds. Producers and mixing-engineers go to great lengths to remove anything sub or ultra-sonic when mixing, just so that tracks do not interfere with each other. (We actually remove a lot more than that, but that’s another story.)
Everyday equipment such as computers, cars, appliances and everything that might potentially make a sound are only engineered to be silent in frequencies that humans can hear. How much noise do they make outside that range?
I am pretty sure that if an individual actually could hear above 22kHz, he would have a miserable life. And he would sure as hell don’t play HD music.
seewhyaudio .
February 13, 2014 at 1:10 pm (11 years ago)Sure if we could hear all above 22K, we’d be in a very noisy world… but we can’t. In the real world, most people can’t hear above about 18Khz, never mind 22Khz!
Don’t get trapped by thinking too much about the frequencies… it’s not where Hi-Res enthusiasts are pointing the argument anyway. The arguments I and others put forward to defend HR music are that you’re getting better ‘focus’ on the frequencies you can hear and the whole effect is clearer. We still don’t have an adequate way of demonstrating this but it’s a lot harder when you’re facing ‘science’ that proves nothing.
One fo the main ‘scientific’ criticisms of HR music is that it suffers from High Frequencies Intermodulation Distortion. The argument is not false, it’s just badly flawed. There is normally such an incredibly tiny amount of distortion that it doesn’t appear to get in the way of enjoying Hi-Res. At least not to me. Or to put it another way, the effects are so negligible as to be not worth worrying about.
The HF energy in a normal music recording is low.
The xiph.org IM demo samples are therefore misleading because in real recordings of music, such HF content barely exists.
Yes, the pitch-shifted sample produces audible IM effects but, and it’s a big but, it’s at maximum amplitude. If you were listening to a normally made music recording which contains little or no real energy above 22Khz, at the levels required to hear audible HF IM distortions, it would be so loud your ears would be pulped in nano-seconds and your head would explode.
I can illustrate this (not the head-exploding of course!) by doing my own samples. Here’s a typical HF recording with piano and voice content in spectrographic (everything above the red line is >22khz):
http://www.seewhyaudio.com/images/misc/HF_IM_01.jpg
Now here’s the levels in waveform:
http://www.seewhyaudio.com/images/misc/HF_IM_02.jpg
Now here’s a high-pass at 22Khz:
http://www.seewhyaudio.com/images/misc/HF_IM_03.jpg
Now a waveform only of the HF content:
http://www.seewhyaudio.com/images/misc/HF_IM_04.jpg
Got it?
Remember that IM distortion is only caused with signals that bear something like a close relationship in amplitude. In order to achieve audible distortion, you need a lot of HF signal. That almost never occurs in nature or in recordings. Thus to supposedly get bad IM distortion out of the normal Hi-Res recording, you’re asking something you can’t hear to have an effect on something you can. Doesn’t work that way, does it?
Don Slepian
August 31, 2013 at 9:58 pm (11 years ago)Justin, Very glad you mentioned Claude Shannon as well as Harry Nyquist. Shannon’s Information Theory should be far better known outside of Mathematical circles. In audio playback (not processing) I’ve been perfectly happy with 16 bits, but I have often liked a higher sampling rate than 44.1Khz. Now anti-aliasing filters are so much better than they used to be, and consequently high frequencies are clearer. I am still getting good sound from my 8 bit Mirage samplers, especially when mixed in with full bandwidth background sounds. Thank you so much for a very thoughtful and perceptive article.
Beth
September 1, 2013 at 5:15 pm (11 years ago)It doesn’t seem revelatory to note that digital has better signal-to-noise ratio than analog or that 16-bit digital has a rather wide dynamic range. We’ve known this for many decades. I think the important discussion is whether the playback technology for these recordings is any good, because that’s what sets the sound.
Glenn Stanton
September 2, 2013 at 7:28 am (11 years ago)Very good explanation! I do agree with Mark though – go 96khz/24bit on the recording side.
Ethan Winer
September 2, 2013 at 8:46 am (11 years ago)Guest wrote: “I think the important discussion is whether the playback technology
for these recordings is any good, because that’s what sets the sound.”
The key here is fidelity, as in “high fidelity.” This is established by a device’s frequency response, distortion, noise, and time-based errors (wow, flutter, and jitter). So to see if a technology is “any good” you measure these four parameters and compare them to the same measurements made for other technologies.
M
September 9, 2013 at 12:28 pm (11 years ago)It is true that digital is the better medium, even considering bit depth, but as with Monty Montgomery’s video, this is really only half the story. What goes into the digital realm is not always comes out. This has a lot to do with Analog to Digital conversion, processing inside the computer (DAW summing, plug-ins, etc.) and them conversion out, or lowering of the bit depth, or heavens forbid, a lowering of the sample rate and resampling. Not to mention going from a lossless to a lossy format. There are many pitfalls along the way, so while we can look at the math and say; “We’ve got more dynamic range than we ever have before.” I think the bigger challenge lies in the education of what makes a good recording to begin with!
Monty Montgomery
M
September 9, 2013 at 12:29 pm (11 years ago)P.S. This was not written by Monty…not sure why his name is showing up there at the end.
Joao Rossi Filho
September 30, 2013 at 1:45 pm (11 years ago)What wasn’t mentioned in this article is that the audio engineers do not increase bit depth seeking low-noise. Bit depth is much more related to stability and robustness of processing algorithms than noise. For example, filters become unstable with a cut-of freq. below 300 Hz for fixed-point 16 bit audio, and this is a very simple example, things can get really nasty when it comes to fractional delay lines and dynamic-range processors, not to mention wave-shappers.
P
September 30, 2013 at 1:47 pm (11 years ago)In your section named (ironically) “All Signal, No Noise”, how about some links to the actual analysis of what you’re talking about? This article, while it makes a good point, doesn’t offer the sort of analysis that would distinguish it from another opinion in an endless debate.
Daniel McBrearty
October 1, 2013 at 2:03 am (11 years ago)There is a bit more to this discussion than meets the eye (or ear). One point (as the author says) is that tape does soft clipping, which is kind to the musical signal, easy on the ear. Converters do hard clipping which is quite the opposite. So you *need* more theoretical dynamic range in a digital chain, because you must be much more cautious about levels. The second point that is neglected here is that your signals have to get through some analogue electronics on both input and output side – at least a few buffers and filters. And this has to be taken into account when talking about the theoretical dynamic range. Having lots of bits to give you 140dB or more in the digital domain may not count for much in reality, because it is very hard to build even a single op amp stage with +/-15V rails and get a real dynamic range of more than about 120dB or so – and that is before you start bringing signals in and out on cables that are several meters long. By then you are dealing with signals which are only uV in amplitude. This is possible in (for instance) radio circuits where required bandwidth is very narrow. One thing people forget about with audio (and which makes it hard) is that you need to preserve a bandwidth of around 10 octaves – AND a wide dynamic range. This is a seriously challenging proposition in the analogue domain where signals need to be sent over distances of meters.
Studiowizard
October 1, 2013 at 3:45 am (11 years ago)Very thoughtful, and ‘Almost’ the whole story, but it fails to point out the inherent distortion created at low levels on low bit resolution. Trying to draw a sine wave with only a handful of plotting points produces a blocky ‘stepped’ waveform – rather like trying to draw a smooth wave with a bar graph. That doesn’t sound like white noise – it sounds like chips frying. Also – as others have pointed out here – increased bit resolution in the record chain is necessary not for audio quality as such, but to allow for the bit depth reduction that results from digital processing and the consequent ’rounding up’ of data that occurs…
Guest
October 12, 2013 at 9:02 am (11 years ago)Right – so this is actually the misconception that Justin is trying to clear up.
Dreadrik
February 13, 2014 at 12:27 pm (11 years ago)There are no stepped waveforms. That is a common misconception, since audio is usually drawn this way on computer screens. Samples in the digital domain are points, not steps. This means that there is actually a perfect curve going between the points. Lower bit rate means ONLY lower dynamic range and lower signal to noise ratio. Take a listen to this 4 bit (yes, four bit) audio sample http://www.audiochrome.net/clips/Venice_4b_noiseshapeE.mp3
Nathan Nanz
July 29, 2017 at 1:47 pm (7 years ago)When you look at the raw output of DACs with low-level program, the waveforms are jaggy and distorted, a product of low-level non-linearity. Not “stair-stepped” but simply errors leading to huge THD. Stereophile Magazine often publishes a -90dBFS sine wave (which is quite audible) at the output of a DAC. It’s not pretty. I’ve uploaded an example plot of a $23,000 DAC from Meridian, called the Ultra DAC, released in 2017.
https://uploads.disquscdn.com/images/55ffeeda24ac813e9745f80bafda1e8295581c0c47107ff9fb1aebed8520fb59.jpg
https://www.stereophile.com/content/meridian-audio-ultra-dac-da-processor-measurements
This is what happens in D-A processing as the waveform approaches the “error floor” of the DAC. In lesser quality DACs, the low-level distortion is far worse, apparent even at -70dBFS. Compare this effect with analog (tape, etc.). As the program approaches the analog noise floor, it remains undistorted — no jaggies. The waveform remains relatively pure, and it falls into the noise.
There’s a theory that people often prefer the “sound” of analog (tape, vinyl, etc.) because it manages low-level signals more linearly than digital (see above). It’s an interesting theory. A holy grail of DAC design is to
eliminate all low-level “jaggy error” distortion, so that even at
-100dBFS or -110dBFS, the program signal remains pure and “jaggy free.” When that happens, digital processing will become far closer to analog reality.
Nathan Nanz
August 1, 2017 at 9:23 pm (7 years ago)When you look at the raw output of DACs with low-level program, the
waveforms are jaggy and distorted, a product of low-level non-linearity.
Not “stair-stepped” but simply errors leading to huge THD. Stereophile
Magazine often publishes a -90dBFS sine wave (which is quite audible) at
the output of a DAC. It’s not pretty. In lesser quality DACs, the low-level distortion is far worse,
apparent even at -70dBFS. Compare this effect with analog (tape, etc.).
As the program approaches the analog noise floor, it remains undistorted
— no jaggies. The waveform remains relatively pure as it falls into
the noise.
There’s a theory that people often prefer the “sound”
of analog (tape, vinyl, etc.) because it manages low-level signals more
linearly than digital (see above). It’s an interesting theory. A holy
grail of DAC design is to eliminate all low-level “jaggy error”
distortion, so that even at -100dBFS or -110dBFS, the program signal
remains pure and “jaggy free.” When that happens, digital processing
will become far closer to analog reality. Sure, dither can help, but not with a DAC’s inherent non-linearity.
Marco Raaphorst
October 1, 2013 at 11:02 am (11 years ago)this is exactly what Monty Montgomery at xiph.org has said some time ago: http://xiph.org/video/vid2.shtml
bcgood
October 2, 2013 at 7:32 am (11 years ago)I get the feeling that the author is claiming that digital audio is superior to analog audio which I certainly disagree with if that is his main point with all of this bit talk. I also find it interesting that he doesn’t even mention DSD audio which is in my experience the best quality of digital audio I’ve ever heard at 1 bit 5.6 MHz. Its pretty simple really, listen to any well recorded album in the last 30 years that was done on tape, console etc and then listen to a new recording done all in Pro Tools, I bet I know which one sounds better..
Khaled Mardam-Bey
October 3, 2013 at 3:47 pm (11 years ago)Thanks to 8-bit Operators, a complete worldwide and older than the internet subculture has been degraded to a “cover band”. Good Job 8-bit Operators… yay…
Brian Meola
November 1, 2013 at 6:45 pm (11 years ago)Everyone can argue until we’re all blue in the face about whether the difference can be heard between 16 and 24-bit audio. Double blind studies aside, there are mastering engineers that run their studios on DC power because they can hear the AC electricity in the walls. Say what you want, but if they tell me they can hear a mouse fart next door I’m not going to tell them that double blind studies say they’re full of crap. All those studies can prove is that MOST people or maybe even almost everyone can’t hear the difference. But the people who REALLY should care about something like this are one in a million.
And regardless of whether we think we can hear the difference in quality, the simple fact is that the difference in quality is technically there. This argument that bit depth has nothing to do with sound quality is absolutely false. Higher bit depth is absolutely not just a matter of a larger SNR. You don’t just get more dB to work with. There are much more lines of resolution that make up the full dynamic range.
16-bit audio uses 65,536 lines of resolution to represent 96dB of dynamic range. That’s about 683 lines per dB. 24-bit audio uses 16,777,216 lines to make up 144dB, which is about 116,508 lines per dB. That is a substantial difference when talking about the amount of lines to accurately quantize a sample. There are much more lines that are much closer together that allow more accurate quantization and less quantization error.
And at the same token, 8-bit audio only has 256 lines to make up 48dB. That’s only FIVE lines of resolution per dB. That’s a massive difference in the amount of error compared to working with 16 MILLION lines of resolution. If you picture the difference in the amount of available points on a chart to map out a wave, you should be able to understand that all the harshness and buzzing in an 8-bit sound is because at that point in resolution, the quantization error is so large that you can noticably hear the inaccuracy, AND the lines of resolution are so far apart that a sine wave will almost start to be drawn with sharp points like a square wave. The argument that the only difference you hear is a raised noise floor is completely invalid. For the reasons above as well as the fact that the actual noise floor in the sense of hearing actual noise in a digital signal only exists artificially. White noise is added to the noise floor of a digital signal to make a quiet signal perceived as more natural, because otherwise the signal would be completely silent. Think about it. Digital audio is a bunch of 1’s and 0’s that represent a point on a chart. Where does the noise come from??
I think the main problem with the author’s train of thought might be that he’s thinking of dB in terms of loudness. He’s thinking that every extra bit gives you an extra 6dB to crank up and hide the noise floor. This is completely backwards. The highest dB in a digital signal is 0. And the extra dB from extra bit depth gets added to the BOTTOM of the signal. This has very little to do with loudness. 0dBFS is the same loudness at 24-bits as it is at 1-bit. 0dBFS is the speaker cone all the way extended. And the digital noise floor is the cone at rest whether the noise floor is at -144dB or -48dB. The distance between the speaker cone at rest and fully extended is a finite measurement. No amount of digital SNR is going to make the speaker get any louder or quieter. So, if you picture a line drawn between these 2 speaker cone points, the lines of resolution in a bit depth represent the amount of times you can slice that line making a smoother transition from rest to extended back to rest. Higher bit depth doesn’t make the line grow. It puts the points closer together, allowing you to map the points on the line much more accurately. So the bit depth is the difference of being able to map a sample on a possible 16 million points on that line versus 256 points.
Where the author is correct is that these bit depths are so good that it’s hard to tell the difference in accuracy between 16 and 24 bit in real world listening environments without super trained freak ears like mastering engineers. But the added bit depth is extremely useful when it comes to quality of audio as well as technique. First of all, the added accuracy minimizes problems like jitter and other artifacts caused by quantization error. Secondly, digital fx render much more accurately and error free at 24-bit for the same reasons. Then there’s the noise floor issue. Jitter and artifacts are more likely to appear in digital audio closer to the noise floor. While 16-bit audio provides a nice SNR, 24-bit audio lets you mix way down around -20 dB. Letting you have at all the dynamic range you want without worrying about head room and knowing that your noise floor is buried all the way down to -144dB. So when mixing around -20dB at 24-bits you still have more SNR underneath than mixing around full scale at 16-bit, plus all the head room to play with. In my experience, this technique makes for a much better mix in a bunch of ways.
And regarding 32-bit Float, the idea of higher resolution at higher bit depths is even more valid when it comes to floating-point resolution. In fixed-integer resolution like 16 and 24-bit, the lines of resolution are evenly distributed across the dynamic range. The quantization error across the whole dynamic range is the same. But with floating-point resolution, higher dBs are represented by more lines for better accuracy. So when dealing with floating-point resolution, the higher dB where your mix is more likely to sit is represented by more lines so waves are drawn more accurately/smoothly instead of wasting lines of resolution way down in the dynamic range where you’re not even going to hear anything anyway.
Kon
April 12, 2015 at 5:05 pm (10 years ago)Thanks for sharing this knowledge… the Internet needs more guys like you, seriously.
Eric D. Ryser
May 29, 2015 at 10:24 am (9 years ago)Yep. I have tin ears, okay? and even I can hear very non-subtle quantization errors when I use my 16 bit recorder, especially when the sound is “Morendo”. Admittedly, this is probably due more to the quality of the digital signal converters than anything, but that doesn’t take away from the fact that, as you point out, given more resolution that conversion will have less error. This article is wrong in it’s basic premise, that bit depth is not “about” resolution…because it’s exactly about resolution.
Physicsonboard
July 30, 2016 at 4:41 pm (8 years ago)This is partially true, but it is not what the studies suggest. The double blind studies showed that a higher proportion of “super listeners” preferred the lower resolution files, no one knows why. OTOH, the idea that one should rely on science when making an audio recording is as ridiculous as making a painting using “color by number.”
MarvSlack
November 5, 2013 at 8:28 am (11 years ago)Great Stuff – Not Breaking News but very well explained. I wonder how many GSers would benefit? – The Mind Boggles!
TimDolbear
December 12, 2013 at 9:21 am (11 years ago)here is the difference between 48bit fixed and 32bit float engines: http://www.youtube.com/watch?v=VjpfsH_4Y8s
qske
December 26, 2013 at 5:40 pm (11 years ago)As a 22 year old that recently came out of university audio production courses, thank you for writing this! We never had anything this in-depth (lame pun intended) about bit depth.
Raji Rabbit
December 27, 2013 at 4:02 am (11 years ago)Great Article!
Scott McChane - Tape Op Mag
January 27, 2014 at 2:09 pm (11 years ago)Awesome article Justin; great follow up to “the Science of Sample Rates”. I only use 32 bit (I call it ‘fold-over’ instead of ‘floating point’) when I’m working with sources that offer unusual amounts of dynamic range – to cover any clipping. In practice, I find the difference in noise floor is inaudible. Hi Ethan.
Phil Dahlen
March 5, 2014 at 10:29 pm (11 years ago)Very interesting article Mr Colletti. Second time I come across and just as informative on second reading. Just one quick question on your use of the expression “dynamic range” when discussing different media. As far as I know, dynamic range usually refers to the difference between the peak level and the RMS, which is an average level. So there is a range below the RMS. When you say that “our beloved vinyl” has an average dynamic range of around 60-70dB, which could be dealt with a bit depth of 11, are you including here the range below the RMS ??
Justin Colletti
March 10, 2014 at 7:10 pm (11 years ago)Hi Phil,
Dynamic Range, in this context at least, tends to be measured from the noise floor of a given device, format, or sound system, and its maximum peak level.
Anything quieter than the noise floor just can’t be heard, and anything louder than the peak level has too much distortion to sound halfway decent.
You might be thinking about the dynamic range of a piece of music, rather than the dynamic range of a sound system or recording format.
Generally, the effective dynamic range of recorded music is going to be significantly lower than the dynamic range of most audio recording formats — Even vinyl.
Hope that clears it up. And thanks for the question,
Justin
JSchmoe
April 27, 2016 at 5:58 pm (9 years ago)“Anything quieter than the noise floor just can’t be heard”
This is completely inaccurate. Think a little more.
Justin C.
April 28, 2016 at 9:28 am (9 years ago)It is indeed my job to think about these things, Mr. Schmoe. If you’d like to make a reasoned counterargument, or provide some evidence to support your assertion, then great! If not, then this doesn’t add much to the conversation.
Until then, yes, the original statement is correct: Any signal that is lower in level than the noise floor will, by definition, be masked by the noise floor and be indistinguishable from the random, full-spectrum noise.
One caveat that may be worth noting is that the noise floor can potentially be at a slightly different level at different frequencies, but the essential concept, and the original statement, still holds, even with this caveat.
Nathan Nanz
July 29, 2017 at 11:42 am (7 years ago)Justin, it’s well-established that program -can- be heard under a “random noise floor.” Sometimes as much as 20-25dB below a noise floor, depending on the nature of the program (e.g., periodic tones in the most ear-sensitive mid-freq band). I actually did a similar experiment recently with -40dBu “broadband, uncorrelated noise” and a -60dBu 2kHz sine wave. Very easy to detect the sine wave 20dB under the noise floor.
Also wondering about your assertion that “in practice, the dynamic range of a 16-bit audio file can reach … as high as 120 dB or more.” Can you elaborate on this? Is there an objective test or study that you can cite? Tks.
Softcore
May 6, 2014 at 2:47 pm (11 years ago)Ι am one of the lucky ones who have seen the Montgomery videos so Im proud to say that most of what I knew, wasnt wrong. Nevertheless, thank you for providing yet one more resource to fight the pseudoscience surrounding digital audio and the tsarlatans that try to make money out of thin air.
Sebastian
September 22, 2014 at 1:14 pm (10 years ago)Incredibly competent article! Unboastful and precise education. Thank you very much for this. Many of those redneck wanna be Engineers in the field should take a leaf out of your book.
John Lardinois
January 5, 2015 at 2:03 pm (10 years ago)You cannot hear the difference between 16-bit, 24-bit, and 32-bit audio. Nor 48kHz, all the way up to 96kHz.
However, I exclusively record in 24/48 and mix in 32fp/96. There is a very solid, scientific reason for this. The reason is that the plugins I use DO have standard operating levels and frequency responses – and most yours do as well.
Let’s start with sample rate. The problem with mixing at 44.1kHz is that your sample rate and anti aliasing filters are not a cliff-like filter. They do not completely behead everything right at 20kHz. In fact, depending on your hardware and A/D converters, they make a gradual low pass filter between 19kHz and 21kHz that looks kind of like a very steep bessel filter.
So when you use plugins to process your audio at 44.1 – let’s say you use a high frequency shelf — every boost that you do to the harmonic content between 19 and 21 is only going to exaggerate the 44.1 cutoff filter’s shape. If you have 44.1kHz audio but you apply that high shelf at 96k – you will notice in spectographs that your anti aliasing filter takes a more natural, friendly shape that treats the harmonic content above 20kHz much more naturally and kindly.
Why is it important to treat the content above 20kHz more naturally and smoothly? Because even though your ears cannot hear them, and cheap speakers cannot play them, these frequencies still exist and perform two functions – 1 in the DAW and 2 in the real world during playback.
For systems that can play frequencies above 20kHz, these supersonic harmonics still vibrate the room around your head even though you cannot hear them. When these frequencies vibrate the walls and chair and cardboard cutout of 1980’s Brett Favre around you, they work in tandem with the frequencies that you CAN hear and amplify or attenuate them in the way nature would if it was a natural acoustical sound.
The effect this has on the frequencies you CAN hear is a sense of clarity – there is clarity and definition in the audio that – although you cannot hear it very well – you can certainly sense it and feel it.
But this reason is mostly bullshit because most consumer speakers don’t reproduce those frequencies anyways. However the concept that the supersonic harmonics affect the quality and reproduction of the human-hearing-range harmonics is very important to this next part.
Plugins, like analog software, can operate well above 20kHz, and are often designed to do so. So when your plugins start processing the “invisible” frequencies above 20kHz, they directly enhance and exaggerate the plugin’s effect on the frequencies you can hear.
What does this mean? Well with just a little easy experimenting, you will notice that trying to EQ a file recorded at 44.1kHz to fit into a heavy-track-count song will be MUCH, much more difficult than mixing the same file that was original recorded at 48 and processed at 96kHz. The reason is that the plugins don’t ONLY affect the frequencies you hear – they also EQ the frequencies above what you can hear. Remember from Acoustical Science 101 that higher harmonics can directly affect the production of lower harmonics. So by setting your session and mixing at 96k – you are also EQing frequencies above 20k, which has an awesome effect on what you can hear. Assuming you’re mixing with proper speakers.
So basically, by mixing at 96k, plugins like EQ, reverb, chorus, and especially tools like harmonic exciters or “enhancers”, will seem to respond to your mixing much, much better and easier with far less processing.
A perfect example – mp3’s cut out a lot of the noise and harmonic content that is normal stored between musical content. Why this is, I don’t know, but it is very clearly evident when you compare an mp3 to an original wav file in a spectrograph. So if you were to take an entire mix and mix all of the tracks as mp3s, and then mix the same song with all 96kHz wav files, you will notice that mp3s require TONS of EQ and processing and really don’t respond well to mixing like the 96k does.
For those of you in the analog world, mixing low sample rate files feels just like mixing audio that was recorded with poor impedance management and matching, except to a less extreme extent. What it means is that tons of the extra information (that we cannot hear) that makes audio respond to our mixing is simply lost.
For my next trick, I’ll explain in an equally boring rant how plugins also have standard operating levels, and why mixing at 32-bits is not necessary, but really handy for proper gain staging. There we will explore concepts as logarithmic conversion scales and inter-sample distortion.
Yes, that’s right – we got rid of (most) of the THD that “plagued” the analog world, but the digital world is no better. Now we have inter-sample distortion – a brand new type of distortion to keep an eye on! mwuahahaha flip your world upside down!
John Lardinois
January 5, 2015 at 2:07 pm (10 years ago)I wrote this a little confusingly. When you record at 44.1k and mix at 96 – you are not EQing any frequencies above 20kHz because they don’t exist.
What you ARE doing, however, is creating more gradual filters, edits, and processes to that cutoff curve that exists between 19 and 21k, like I mentioned previously. Basically, all of this results to more definition, resolution, and gain at the frequencies between 20 and 21 – and even higher if you record at 48.
This makes mixing MUCH easier.
John Lardinois
January 5, 2015 at 2:08 pm (10 years ago)Again the difference in mixing at 44.1 and 96 is something you can feel, not hear so much. If you find that you have a difficult track that you have to apply tons of EQ and processing to and it still won’t fit right into the track – it seems like no matter now much EQ you put on it, it doesn’t make a difference – then there is either a sample rate problem or an impedance problem.
T_Thrust
January 6, 2015 at 3:39 pm (10 years ago)I thought the nyquist filter is at 22k?
John Lardinois
January 9, 2015 at 10:44 am (10 years ago)It is – that’s why the sample rate is 44.1 and not 40. I simply was using numbers that were consistent with 20kHz human hearing range so as to not confuse those who are not familiar with how nyquist filters and sample rates work.
I figured there are people who are reading this who have never heard of a nyquist filter, but know that human hearing goes up to 20k (common knowledge).
I meant it as a way to simplify the explanation for the readers who are new to digital audio theory. So, yes, you are correct. I merely meant it as a simpler, cleaner response for the new guys.
T_Thrust
January 9, 2015 at 7:02 pm (10 years ago)ahh, got ya.
preferred user
August 5, 2015 at 7:48 pm (9 years ago)16/44.1 lower Nyqist rate is close @ 22.5kHz i.e. ½ of 44.1kHz
George Piazza
March 10, 2017 at 2:00 pm (8 years ago)I have one question for you John: Do you convert your files to 96 kHz before mixing them, or do you simply set your DAW to output a 96kHz file?
If you do the latter, ask yourself – Where is the DAW converting the data into 96 kHz? Before the first mixing calculation? Really?
Or, as is much more likely, the whole mix is happening at the original sample rate, then the DAW is up-converting the final output to 96 kHz? Therefore, none of the EQs & other processors are ever seeing 96 kHz (except for the ones that have internal up-sampling as part of their processing). All you are doing is up-converting a stereo file after the mixing.
I have seen a number of people who say they do what you do, but if you check your CPU usage, does it double when you mix out at double the original file sample rates? Or at least go up substantially, taking into account the number of plugins that already up-sample – down-sample the data stream? And if the session (and converter) are still set to 48 kHz, is it reasonable to assume that you are getting 96 kHz processing throughout? Even if you set the DAW to 96 kHz playback, you are now playing back 48 kHz files at twice their speed! Without changing the actual processing sample rate of the calculations. (and the ‘mix’ file would probably sound rather odd.. you know, like the chipmunks on meth!).
I have yet to see a DAW manufacturer that unequivocally specifies the actual location of the up-sampling when the output medium is set at a higher sample rate, but the logic dictates that 48 kHz files playing back at 48 kHz will be processed at 48 kHz, then up-sampled to 96 kHz upon output.
Therefore, the only way to assure all processing takes place at 96 kHz is to batch up-sample every file, set the DAW at the new sampling rate (96 kHz) and then mix. Hope you consolidate all your files first!
Bob Fridz
October 1, 2015 at 11:17 am (9 years ago)Nice article but aren’t a lot of people failing to mention or realize that in a studio people often stack up multiple tracks to make an arrangement. This can be 100+ tracks nowadays in pop music, but it happens in all genres.
One might not be able to hear the difference between a 16 bit finished track or a 24 bit finished track, but I am 1000% sure everyone can hear the difference between a mix built up out of 100+ 16bit tracks or a 100+ 24 bit tracks. Same goes for 44.1 up to 192khz.
Record a drumkit with 15 mics (close, mid and room) and have a drummer play the same beat and fills. Record a section at 16bit 44.1khz and record a similar section at 24bit 192khz.
I will put money on this: everyone will hear the difference! And no it’s not magic. 24/192 isn’t amazing, it’s just the most accurate way of capturing sound.
Downgrading a 24/192 mix to 16/44.1 afterward will still sound better than doing the whole process at 16/44.1 from the start.
Mark K.
June 14, 2016 at 2:56 pm (8 years ago)“Any signal that is lower in level than the noise floor will, by definition, be masked by the noise floor and be indistinguishable from the random, full-spectrum noise.”
That’s utter nonsense. Humans can pick up patterns WAY below the noise floor. E.g:
http://ethanwiner.com/audibility.html
John Morris
April 16, 2017 at 12:54 am (8 years ago)I have been trying to educate people on this for years. If you think this is bad try explaining to amateur engineers that 0dbfs (digital full scale) doesn’t equal 0vu. 0vu or rather 0dbu for 24 bit is -18dbfs RMS (average level not peak) I tell them their converters will sound better if they run them at the level they were designed to operate at. Average at -18dbfs (between -22 and – 12dbfs) and don’t peak beyond -6dbfs but I get this, “The closer you get to 0dbfs the more bits you use, so the better it sounds…” amateur engineers recording too hot has become a big problem. Even some professionals with million dollar studios, who should know better are doing this “max it out to zero” foolishness.